source: visual-numpy.md authored by kevingo
本文翻译自 Jay Alammar 的 A Visual Intro to NumPy and Data Representation 这篇部落格文章。对于从事数据分析或机器学习的朋友来说,numpy 一定是不陌生的 Python 套件。不管是数据处理所使用的 Pandas 、机器学习用到的 scikit-learn 或是 deep learning 所使用的 tensorflow 或 pytorch,底层在数据的操作或储存上,大多会用到 numpy 来做科学的操作。而本篇文章以图文并茂的方式详细说明了在 numpy 中必学的操作,并且告诉你 numpy 的数据结构如何用来储存文字、图片、声音等重要的数据,如果你有心学习数据科学或机器学习,一定要把 numpy 学好。希望透过此文的分享,让大家在学习 numpy 的过程中能够更加清楚其操作与用途。

NumPy 套件是 python 生态系中针对数据分析、机器学习和科学计算的重要角色。它大量简化了向量和矩阵的操作运算,某些 python 的主要套件大量依赖 numpy 作为其架构的基础 (例如:scikit-learn、SciPy、Pandas 和 tensorflow)。除了可以针对数据进行 切片 (slice) 和 切块 (dice) 之外,熟悉 numpy 还可以对使用上述套件带来极大的好处。
在本文中,我们会学习 numpy 主要的使用方式,并且看到它如何用来表示不同类型的数据 (表格、影像、文字 ... 等) 作为机器学习模型的输入。
import numpy as npN维数组(阵列)¶
建立阵列¶
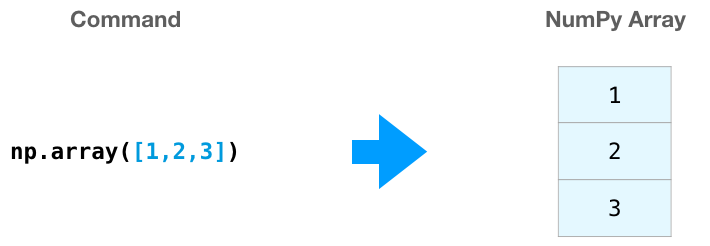
我们可以透过 np.array() 并传入一个 python list 来建立一个 numpy 的阵列 (又叫「N维数组」 ndarray ),如下所示:
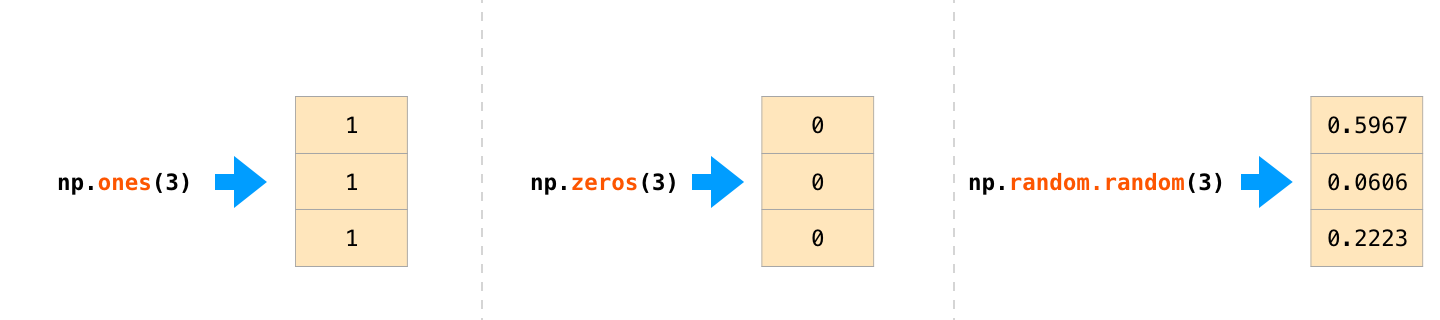
通常我们希望 numpy 能够初始化阵列的值,因此它提供了像 ones()、zeros() 和 random.random() 等方法。我们只要传入希望产生的值即可:
一但我们建立了阵列后,就可以透过有趣的方式来操作它们。
阵列运算¶
让我们建立两个 numpy 阵列来展示如何进行运算,分别是 data 和 ones:

将这两个 numpy 阵列依照位置相加 (即每一行相加),只要使用 data + ones 即可:
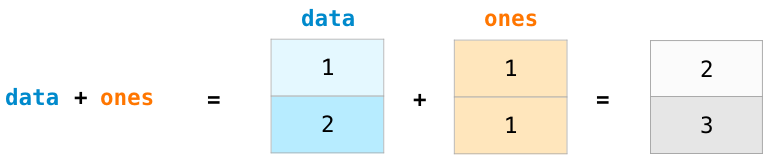
当我开始学习 numpy 后,我发现这样抽象的思考让我不需要使用类似迴圈的方式来进行计算,如此一来,我可以透过更高层次的角度来思考问题。
而除了相加之外,我们还可以进行以下操作:

通常的情况下,我们会希望一个阵列可以和单一数字进行运算 (即向量和纯量之间进行运算)。比如说,阵列中的数字是以英里为单位的距离,而我们希望将其转换为公里,只需要透过 data * 1.6 即可:

看到 numpy 是如何处理这样的操作了吗?这个概念称为 广播 (broadcasting),它非常有用。
索引¶
我们可以像 python 的 list 进行切片一样,对 numpy 的阵列进行索引和切片:

聚合 (aggregation)¶
Numpy 另外一个好处是提供了聚合函式:

除了 min、max 和 sum 之外,你还可以使用像是 mean 来得到平均值,prod 来得到所有元素的乘积,std 来得到标准差,以及其他更多的功能。
更多维度:矩阵¶
上述我们所看到的范例都是在单一维度的向量上进行,而 numpy 之美在于这些操作可以扩展到任意维度的数据上。
建立矩阵¶
我们可以透过传递 python 的 list 让 numpy 建立一个矩阵:
np.array([[1,2],[3,4]])
我们也可以使用上面提到的方法 (ones()、zeros() 和 random.random()),只要传入一个 tuple 来描述我们建立矩阵的维度即可:

矩阵运算¶
当两个矩阵的大小相同时,我们可以透过运算元 (+ - * /) 来对其进行相加或相乘。Numpy 是透过 position-wise 的方式进行运算:
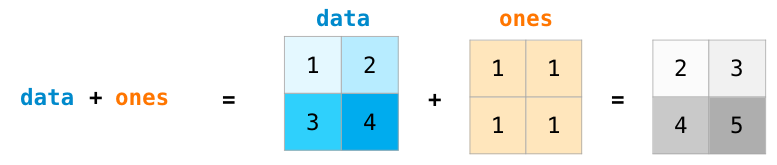
我们也可以针对不同大小的矩阵进行运算,前提是其中一个矩阵的的某一维度为 1 (比如说其中一个矩阵只有一行或一列),如此一来,numpy 就可以透过广播的机制来进行运算:

内积 / 点积(Dot Product)¶
算术运算和矩阵乘法一个最主要的区别在于内积。在 Numpy,每一个矩阵都有一个 dot() 方法,我们可以透过它让矩阵之间进行内积运算:

我在上图的右下角显示了矩阵的维度来强调相临的两个维度必须相同,你可以把上述的运算看作:

矩阵索引¶
当我们在矩阵的运算时,索引和切片变得相当有用:
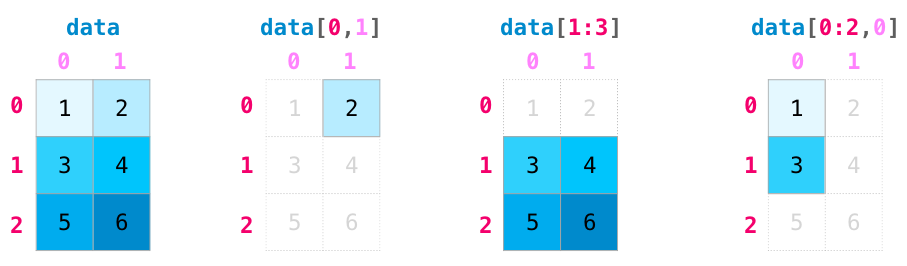
矩阵聚合 (aggregation)¶
我们可以针对矩阵进行聚合操作,就和向量一样:

我们不仅可以针对整了矩阵的值进行聚合操作,也可以透过 axis 参数来对行或列进行操作:

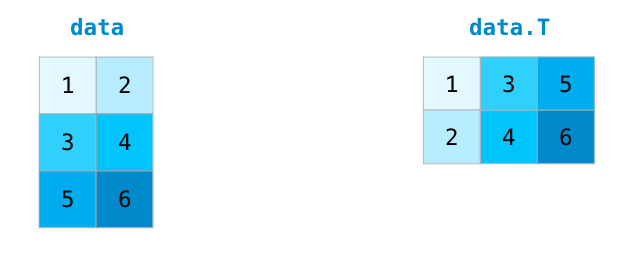
置换和变形¶
矩阵经常会进行的操作是转置,当我们要对两个矩阵进行内积操作时,经常会需要将其共享的维度对齐。在 Numpy 中,有一个方便的属性 T 可以得到一个转置矩阵:
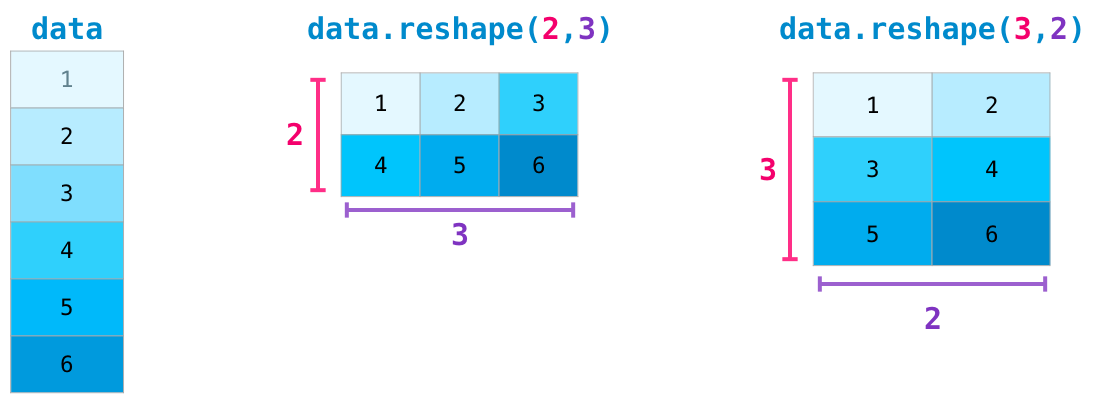
在更进阶的使用情境中,你可能需要变换某个特定矩阵的维度。这是因为在机器学习的应用中,特定的模型会需要特定的输入维度,而这个维度可能跟你原本的数据集不同。在 numpy 中,reshape() 方法可以很方便地让你变更数据的维度。你只要将所需的维度传入此方法即可,也可以传入 -1,numpy 会自动判断出正确的维度:
更高维度¶
上述所提到的任何操作,都可以套用在任意的维度上,其核心的数据结构叫做 ndarray (N 维阵列)。

在很多情况下,处理一个新的维度只需要在 numpy 的函数中多增加一个逗号:
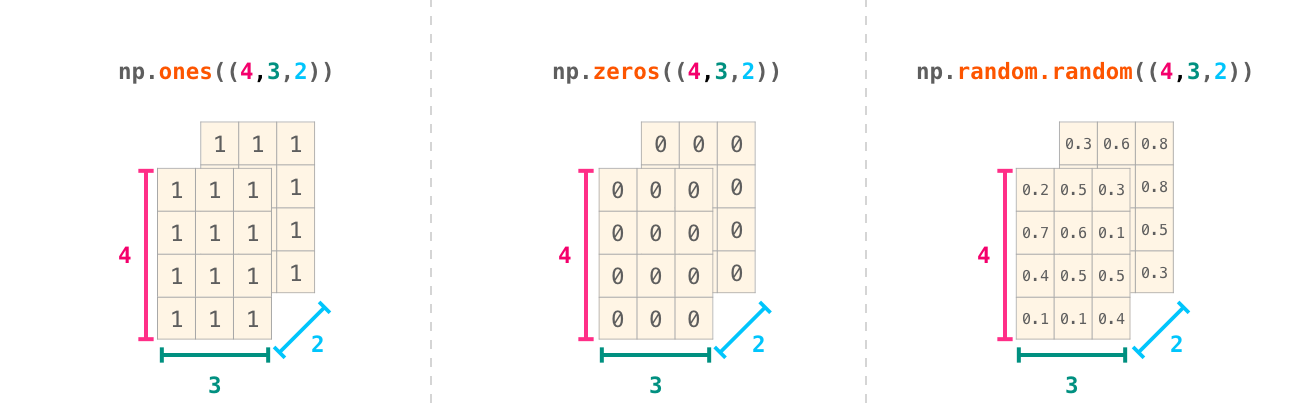
注意:当你要显示一个 3 维的 numpy 阵列时,其显示方式和在此文中所见不同,numpy 会从最后一维开始呈现,意思就是 np.ones((4,3,2)) 会显示如下:
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])实际用法¶
作为学习到目前的回报,底下是一些透过 numpy 阵列来完成特定任务的范例。
公式¶
实作需要透过阵列或向量来完成的数学公式是 numpy 主力的战场之一,这也是为什麽 numpy 在 python 的社群中会被用在科学运算的原因。举例来说,均方差是监督式学习来处理回归问题的核心:
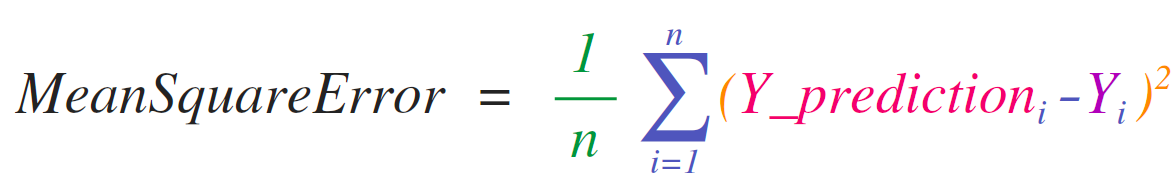
实作此公式在 numpy 中很容易:

这优雅的地方在于,numpy 不在乎 predictions 和 labels 裡面是一个还是一千个值 (只要它们的大小相同)。我们接下来会一步步拆解这个范例:

predictions 和 labels 向量都有三个值,也就是 n = 3,在我们进行相减后,结果如下:

接著对向量进行平方,得到:

接著进行加总:

此结果即是 prediction 的误差值,以及此模型的质量。
数据表示¶
想想看所有你需要用来处理和建立模型的数据 (例如:表格、影像、声音...等等),它们有许多都非常适合使用 n 维阵列来表示:
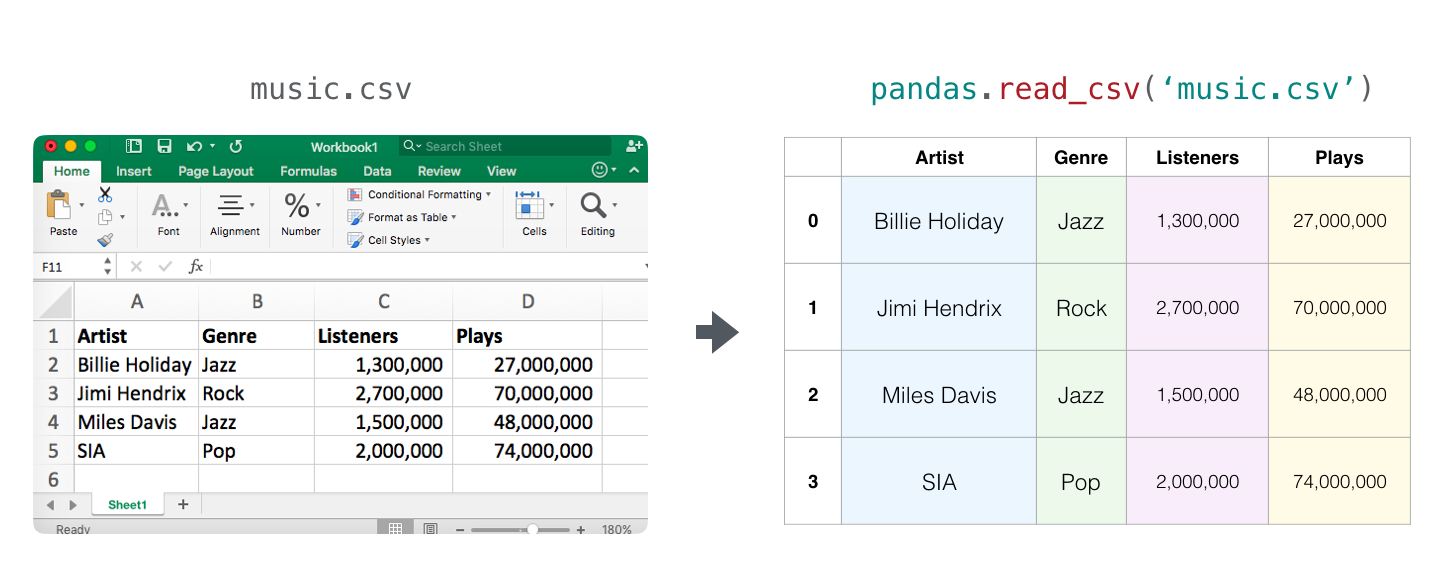
表格和电子试算表¶
- 电子试算表或是表格是一个二维阵列。每一个电子试算表中的工作表都可以有他自己的变数。在 python 中处理这类型数据最热门的方法是使用 pandas dataframe,它正是建构在 numpy 之上的套件。
声音和时序数据¶
- 声音是一维阵列的档案格式。阵列中的每一个值代表声音讯号的一小部分。CD 品质的声音每一秒会有 44,100 笔数据,每一笔数据是 -32767 到 32768 的整数。换句话说,如果你有一个长度十秒的 CD 声音档案,你可以透过 10 * 44,100 = 441,000 的 numpy 阵列来读取数据。如果想要读取声音档案的第一秒,只需要将数据读入 numpy 阵列中,然后透过
audio[:44100]就可以读取了。
底下是一段声音档案:
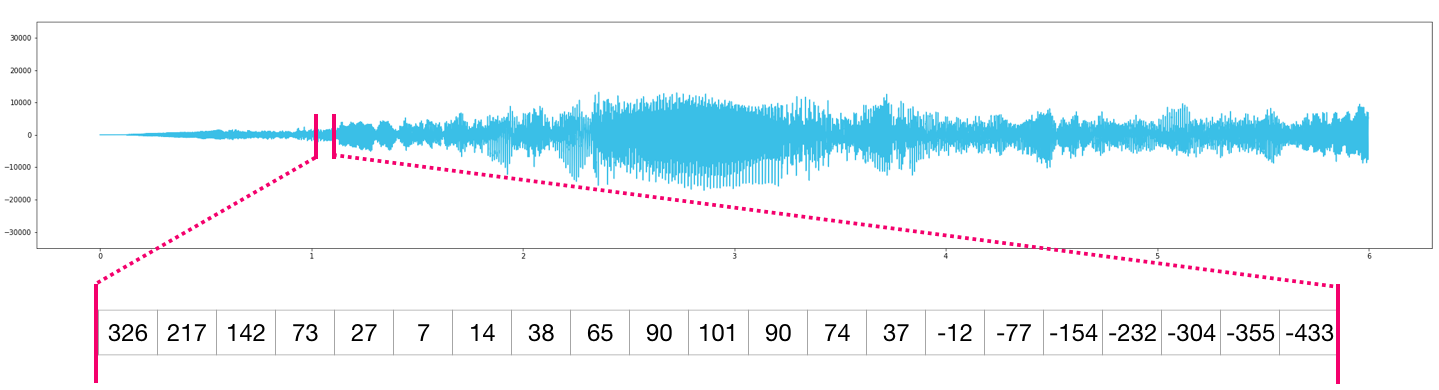
而时间序列的数据也是相同的处理方法 (比如说,股价随著时间波动的数据)。
图片¶
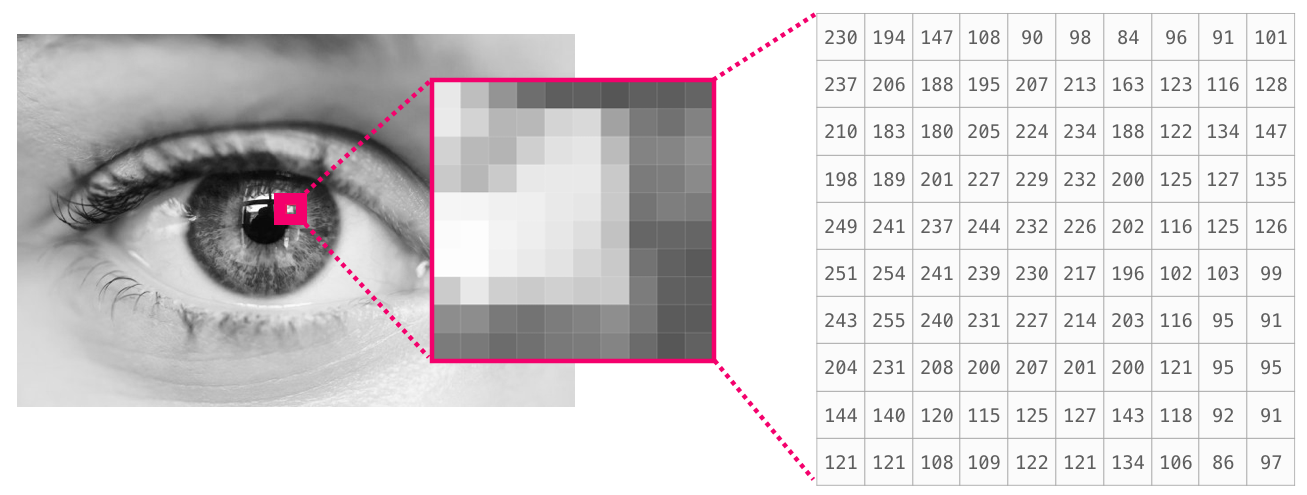
- 一张图片是一个像素所形成的矩阵 (长 * 宽)
- 如果图片是黑白的 (也就是灰阶图片),每一个像素可以透过单一数字表示 (通常会介于 0 (黑色) 到 255 (白色) 之间)。当你想要撷取一张图片左上角 10 x 10 像素的图片时,只要透过 numpy
image[:10, :10]即可:
- 如果图片是黑白的 (也就是灰阶图片),每一个像素可以透过单一数字表示 (通常会介于 0 (黑色) 到 255 (白色) 之间)。当你想要撷取一张图片左上角 10 x 10 像素的图片时,只要透过 numpy
底下是一张灰阶图片的范例:
- 如果图片是彩色的,每一个像素会用三个数字来表示 - 红色、绿色和蓝色。这种情况下,我们需要一个三维阵列 (因为每个位置只能包含一个数字)。所以一张彩色图片会透过 ndarray 的数据结构来表示:(长 宽 3)

语言¶
如果我们想要处理文字,状况会有一点点不一样。当你想要透过数值来表示文字的时候,你需要建立一个词库 (这个词库指的是模型需要用到的所有单字的列表),还有一个 嵌入的步骤。让我们一步步来看如何处理底下这个诗句:
“Have the bards who preceded me left any theme unsung?”
在模型想要用数值来表示上面该诗句之前,需要先看过大量的文字。我们可以处理一个小的数据集来看看要怎麽建立一个词库(共有 71,290 个字):

上面的诗句可以被分割成一个 token 的阵列 (基于某些规则所分割出来的字或部分字):

接著,我们用词库中的 id 来取代每个字:

这一些 id 对于模型来说没有提供有用的资讯,所以在交给模型训练之前,我们需要使用 word2vec embedding 来取代原本的 id 表示法 (在这个范例中是一个 50 维的 embedding):

你可以看到这个 numpy 阵列的维度是 [embedding_dimension x sequence_length],在实务上,呈现的样子可能不太一样,但在这裡为了视觉的一致性,我透过下图来表示其结果。由于效能的考量,深度学习模型会保留等同于 batch 大小第一维 (因为当多笔训练数据时,模型就可以透过平行化的方式来训练)。在这种情况下,reshape() 就变得很有用,比如说像 Bert 模型的输入维度就会是 [batch_size, sequence_length, embedding_size]。
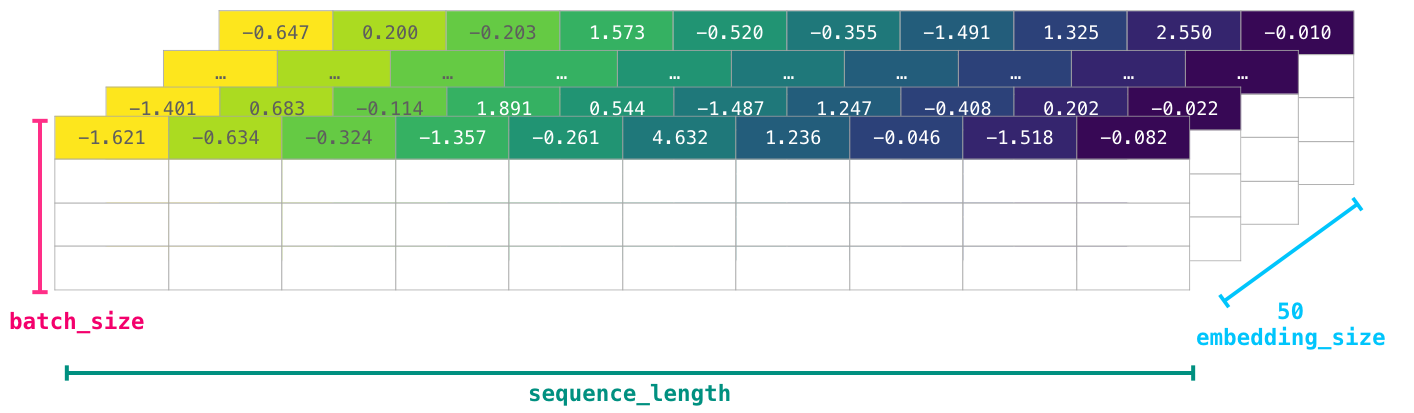
现在上述的诗句被表示成数值形式,模型就可以对其进行训练。其他行虽然目前是空白的,但它将会被更多的训练数据给填满。