3.1. 介绍¶
北京市作为中国的首都和政治、经济、文化中心,其房价一直备受关注。本实验将使用机器学习方法对北京市住房价格进行预测分析,帮助理解影响房价的关键因素。
3.2. 知识点¶
- 数据预处理和特征工程
- 多元线性回归模型
- 模型评估和验证
- 特征重要性分析
- 房价预测可视化
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体(使用 macOS 自带字体)
plt.rcParams['font.sans-serif'] = ['PingFang HK', 'Songti SC', 'Arial Unicode MS', 'Heiti TC'] # 优先使用宋体-简
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.style.use('ggplot') # 设置图表风格
pd.set_option('display.max_columns', 50) # 显示最多50列
# 初始化 Faker 库
fake = Faker('zh_CN') # 使用中文数据
Faker.seed(42) # 设置随机种子确保结果可重现
print("库导入成功!")
库导入成功!
3.3. 数据集读取与划分¶
# 通过requests使用代理下载CSV
url = 'https://gist.githubusercontent.com/ffutop/870eb32f8ef6e1cfd1fc9e40d2fa63e5/raw/1cac678610a703bde5b366f2c312a211034af9b1/challenge-1-beijing.csv'
df = pd.read_csv(url)
df.head()Loading...
print(f"数据维度: {df.shape}")
print("\n前5行数据:")
display(df.head())
print("\n数据摘要:")
display(df.info())
print("\n描述统计:")
display(df.describe(include='all'))Loading...
target_column = "每平米价格"
features = df[df.select_dtypes(include=np.number).columns.drop([target_column])]
target = df[target_column]
features.columnsIndex(['公交', '写字楼', '医院', '商场', '地铁', '学校', '建造时间', '楼层', '面积'], dtype='object')pd.concat([features, target], axis=1).head()Loading...
from sklearn.model_selection import train_test_split
# 定义特征矩阵和目标变量
X = features # 特征矩阵,包含所有数值型预测变量
y = target # 目标变量,即"每平米价格"
# 将数据集拆分为训练集和测试集
# test_size=0.3: 30%的数据用于测试,70%用于训练
# random_state=42: 设置随机种子以确保结果可复现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 打印各个数据集的形状,以验证拆分是否正确
# X_train: 训练集特征矩阵的形状 (行数,列数)
# y_train: 训练集目标变量的形状 (行数,)
# X_test: 测试集特征矩阵的形状 (行数,列数)
# y_test: 测试集目标变量的形状 (行数,)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)(2100, 9) (2100,) (900, 9) (900,)
3.4. 模型训练及预测¶
Sklearn 进行线性回归预测¶
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(X_train, y_train)Loading...
print("\n参数个数: ", len(model.coef_))
# 检查每个预测模型的系数:表示每个特征变化一个单位时,目标变量(每平米价格)的变化量
for name, coef in zip(X_train.columns, model.coef_):
print(f"{name}: {coef}")
# 检查截距项
print("\nIntercept: ", model.intercept_)
参数个数: 9
公交: -458.04903694803835
写字楼: 239.74082733385274
医院: 527.4015370479757
商场: -8.446576771348191e-13
地铁: 1903.714501777691
学校: 389.36758062034033
建造时间: -6.079461601742742
楼层: 109.83878995174076
面积: 38.83877919439944
Intercept: 57328.912826981905
# 获取测试集的真实目标值(转为numpy数组,便于后续计算)
y_true = y_test.values
# 使用训练好的线性回归模型对测试集特征进行预测,得到预测值
y_preds = model.predict(X_test)
3.5. 模型评价¶
平均绝对百分比误差 MAPE : MAPE 是一个百分比值,因此比其他统计量更容易理解。例如,如果 MAPE 为 5,则表示预测结果较真实结果平均偏离 5%。MAPE 的计算公式如下:
其中, 表示真实值, 表示预测值, 则表示值的个数。MAPE 的值越小,说明预测模型拥有更好的精确度。
3.5.1 Sklearn¶
from sklearn import metrics
def evaluate_regression(y_true, y_preds):
"""计算并打印多个回归评估指标"""
mse = metrics.mean_squared_error(y_true, y_preds)
rmse = np.sqrt(mse)
mae = metrics.mean_absolute_error(y_true, y_preds)
mape = metrics.mean_absolute_percentage_error(y_true, y_preds)
r2 = metrics.r2_score(y_true, y_preds)
print("回归模型评估指标:")
print(f"MSE: {mse:,.4f}")
print(f"RMSE: {rmse:,.4f}")
print(f"MAE: {mae:.4f}")
print(f"MAPE: {mape*100:.2f}%")
print(f"R²: {r2*100:.2f}%")
return {"mse": mse, "rmse": rmse, "mae": mae, "r2": r2}
# 使用示例
metrics_dict = evaluate_regression(y_true, y_preds)
# MAE:衡量预测误差和绝对值大小的指标
# MSE:相比于MAE,MSE对大误差的惩罚更重,MSE会比MAE更大
# MAPE:模型的平均百分比误差,评估预测结果的相对准确性回归模型评估指标:
MSE: 616,795,311.2921
RMSE: 24,835.3641
MAE: 19619.9207
MAPE: 46.96%
R²: 19.95%
评估指标详解¶
这段代码是用于评估机器学习模型性能的,它计算了几个不同的回归评估指标:
均方误差 (MSE, Mean Squared Error): 计算预测值与真实值差值的平方的平均值。由于平方操作,MSE对大误差的惩罚更重,因此MSE对大误差特别敏感。
- 公式:
- 含义:值越小表示模型越精确;完美预测时MSE=0
平均绝对误差 (MAE, Mean Absolute Error): MAE计算预测值与真实值之间的绝对差值的平均值。
- 公式:
- 含义:MAE比MSE对异常值更不敏感,提供更直观的误差度量
平均绝对百分比误差 (MAPE, Mean Absolute Percentage Error): 计算预测值与真实值差值相对于真实值的百分比的平均值。
- 公式:
- 含义:误差相对于实际值的百分比。代码中乘以100并格式化为保留两位小数的百分比形式。
决定系数 (R², R-squared): 衡量模型解释因变量变异程度的统计量。
- 公式:
- 含义:R²衡量模型解释因变量变异性的程度。取值范围通常在0到1之间,越接近1表示模型的拟合效果越好。代码中将R²值乘以100并格式化为百分比形式。
指标之间的关系¶
- MSE vs MAE:MSE由于平方项的存在,对大偏差的惩罚更为严厉,因此MSE通常大于MAE。
- MAPE:提供相对误差视角,对于房价预测等问题特别有用,因为它衡量的是预测与实际值的相对偏差。
- R²:衡量模型对数据变异性的解释能力,是了解模型总体表现的重要指标。
评估指标结果解读¶
- MSE (均方误差): 616,795,311.29
- 这是一个很大的数值,表示预测值与实际值的平方差平均值很高
- 由于平方运算,这个值通常会比较大,特别是对于房价这种数值较大的预测目标
- 单独看这个数值不直观,需要结合其他指标和数据规模来理解
- MAE (平均绝对误差): 19,619.92
- 表示模型预测的房价与实际房价平均相差约19,620元/平方米
- 这是最直观的误差衡量,告诉你预测值平均偏离了多少
- MAPE (平均绝对百分比误差): 46.96%
- 表示预测值平均偏离实际值的程度为46.96%
- 这是一个相对较高的误差率,意味着模型平均会高估或低估接近一半的房价
- 通常,MAPE低于10%被认为是非常好的预测,而超过40%则表示预测精度较低
- R² (决定系数): 19.95%
- 表示模型只能解释约19.95%的房价变异
- 通常R²接近1(或100%)表示模型拟合得很好
- 19.95%是一个较低的值,说明模型对房价的预测能力有限,还有约80%的变异无法被现有特征解释
- 综合解读:
这个模型的预测精度相对较低,平均误差接近50%。模型对数据的拟合度不高,只能解释约20%的房价变化。模型预测的房价与实际房价平均相差约19,620元/平方米。可能需要添加更多相关特征、调整模型参数或尝试更复杂的模型来提高预测精度。
metrics.get_scorer_names()['accuracy',
'adjusted_mutual_info_score',
'adjusted_rand_score',
'average_precision',
'balanced_accuracy',
'completeness_score',
'explained_variance',
'f1',
'f1_macro',
'f1_micro',
'f1_samples',
'f1_weighted',
'fowlkes_mallows_score',
'homogeneity_score',
'jaccard',
'jaccard_macro',
'jaccard_micro',
'jaccard_samples',
'jaccard_weighted',
'matthews_corrcoef',
'max_error',
'mutual_info_score',
'neg_brier_score',
'neg_log_loss',
'neg_mean_absolute_error',
'neg_mean_absolute_percentage_error',
'neg_mean_gamma_deviance',
'neg_mean_poisson_deviance',
'neg_mean_squared_error',
'neg_mean_squared_log_error',
'neg_median_absolute_error',
'neg_negative_likelihood_ratio',
'neg_root_mean_squared_error',
'neg_root_mean_squared_log_error',
'normalized_mutual_info_score',
'positive_likelihood_ratio',
'precision',
'precision_macro',
'precision_micro',
'precision_samples',
'precision_weighted',
'r2',
'rand_score',
'recall',
'recall_macro',
'recall_micro',
'recall_samples',
'recall_weighted',
'roc_auc',
'roc_auc_ovo',
'roc_auc_ovo_weighted',
'roc_auc_ovr',
'roc_auc_ovr_weighted',
'top_k_accuracy',
'v_measure_score']3.5.2 statsmodels¶
import statsmodels.api as sm
# 添加常数项,以拟合截距
X_train_const = sm.add_constant(X_train)
# 创建模型并拟合
model2 = sm.OLS(y_train, X_train_const)
result2 = model2.fit()
# Coef: 显示每个自变量的估计系数,即每个自变量对因变量的影响大小
print("Model parameters:", result2.params)
# 输出模型摘要
print(result2.summary())Model parameters: const 5.732891e+04
公交 -4.580490e+02
写字楼 2.397408e+02
医院 5.274015e+02
商场 9.791973e-11
地铁 1.903715e+03
学校 3.893676e+02
建造时间 -6.079462e+00
楼层 1.098388e+02
面积 3.883878e+01
dtype: float64
OLS Regression Results
==============================================================================
Dep. Variable: 每平米价格 R-squared: 0.199
Model: OLS Adj. R-squared: 0.196
Method: Least Squares F-statistic: 65.11
Date: Mon, 13 Oct 2025 Prob (F-statistic): 1.58e-95
Time: 18:33:15 Log-Likelihood: -24293.
No. Observations: 2100 AIC: 4.860e+04
Df Residuals: 2091 BIC: 4.865e+04
Df Model: 8
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 5.733e+04 8310.656 6.898 0.000 4.1e+04 7.36e+04
公交 -458.0490 103.241 -4.437 0.000 -660.514 -255.584
写字楼 239.7408 59.913 4.001 0.000 122.245 357.237
医院 527.4015 131.129 4.022 0.000 270.245 784.558
商场 9.792e-11 1.41e-11 6.932 0.000 7.02e-11 1.26e-10
地铁 1903.7145 1153.080 1.651 0.099 -357.590 4165.019
学校 389.3676 63.710 6.112 0.000 264.425 514.310
建造时间 -6.0795 4.092 -1.486 0.138 -14.104 1.945
楼层 109.8388 64.849 1.694 0.090 -17.336 237.014
面积 38.8388 4.490 8.650 0.000 30.034 47.644
==============================================================================
Omnibus: 435.303 Durbin-Watson: 2.044
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1011.162
Skew: 1.148 Prob(JB): 2.69e-220
Kurtosis: 5.506 Cond. No. 6.80e+19
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The smallest eigenvalue is 1.83e-30. This might indicate that there are
strong multicollinearity problems or that the design matrix is singular.
3.5.3 pycaret¶
from pycaret.regression import *
exp_setup = setup(data = df, target = '每平米价格')
all_metrics = get_metrics()Loading...
plt.rcParams['font.sans-serif'] = ['PingFang HK', 'Songti SC', 'Arial Unicode MS', 'Heiti TC']
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['axes.unicode_minus'] = False
# 创建模型
lr_model = create_model('lr') # 线性回归模型
# 残差图 - 检查误差分布
plot_model(lr_model, plot='residuals')
# 预测误差图 - 查看预测与实际值的对比
plot_model(lr_model, plot='error')
# 特征重要性图 - 了解哪些特征影响最大,使用PyCaret的plot_model时指定字体
plot_model(lr_model, plot='feature')
# 学习曲线 - 评估模型的泛化能力
plot_model(lr_model, plot='learning')
# 决策树可视化(如果使用决定树模型)
dt_model = create_model('dt')
plot_model(dt_model, plot='tree')Loading...
compare_models(include = ['lr', 'xgboost', 'rf', 'et', 'lightgbm'])Loading...
3.5.3 Shap¶
import shap
print("Model coefficients:\n")
for i in range(X.shape[1]-1):
print(X.columns[i], "=", model.coef_[i].round(5))Model coefficients:
公交 = -458.04904
写字楼 = 239.74083
医院 = 527.40154
商场 = -0.0
地铁 = 1903.7145
学校 = 389.36758
建造时间 = -6.07946
楼层 = 109.83879
# 提取系数
coef = model.coef_
feature_names = X_test.columns
# 创建系数DataFrame并排序
coef_df = pd.DataFrame({'特征': feature_names, '系数': coef})
coef_df = coef_df.reindex(coef_df['系数'].abs().sort_values(ascending=False).index)
# 绘制水平条形图
plt.figure(figsize=(10, 8))
plt.barh(coef_df['特征'], coef_df['系数'])
plt.xlabel('系数值')
plt.ylabel('特征')
plt.title('线性模型系数大小')
plt.axvline(x=0, color='gray', linestyle='--')
plt.tight_layout()
plt.show()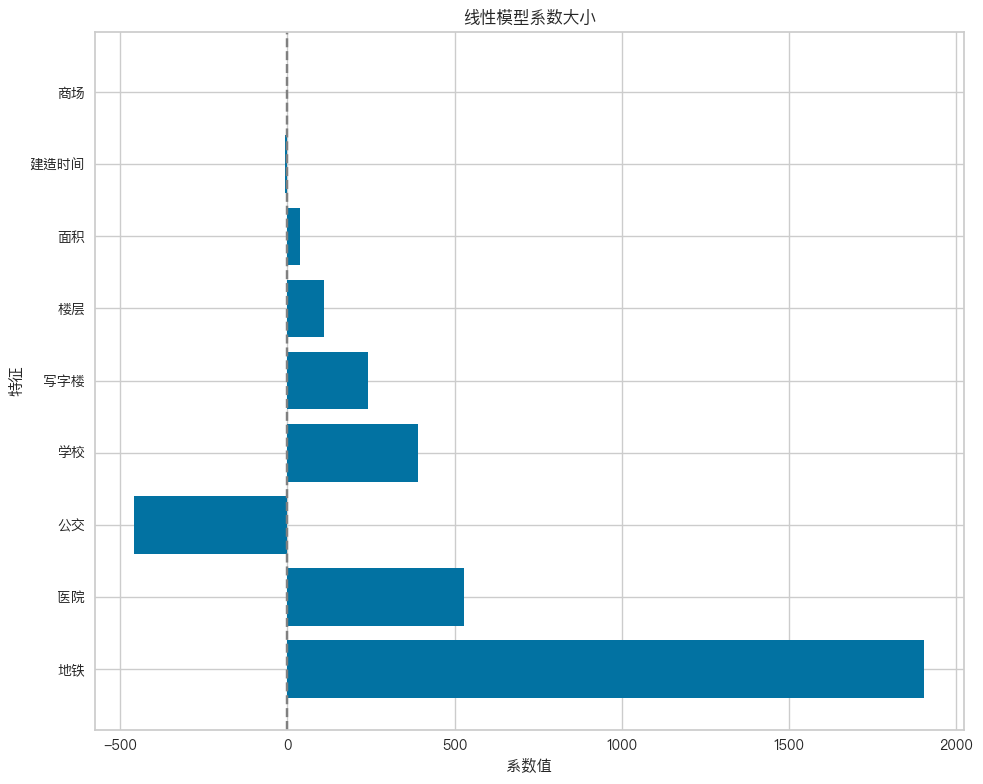
# 2. SHAP值可视化
# SHAP值提供了更精细的特征贡献分析,特别是对多样本的整体解释。
import matplotlib.pyplot as plt
import shap
plt.rcParams['font.sans-serif'] = ['PingFang HK', 'Songti SC', 'Arial Unicode MS', 'Heiti TC']
plt.rcParams.update({'font.size': 10}) # Set desired font size
# 创建解释器
explainer = shap.LinearExplainer(model, X_test)
shap_values = explainer.shap_values(X_test)
# 摘要图 - 展示所有特征的整体影响
shap.summary_plot(shap_values, X_test, plot_type="bar") # 条形图版本
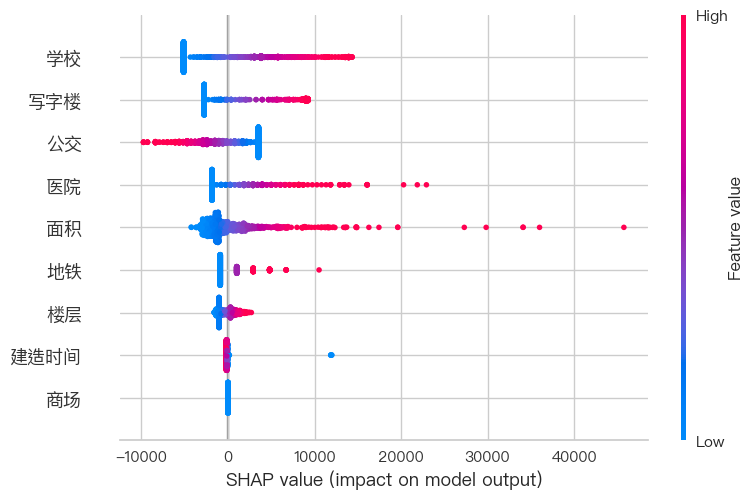
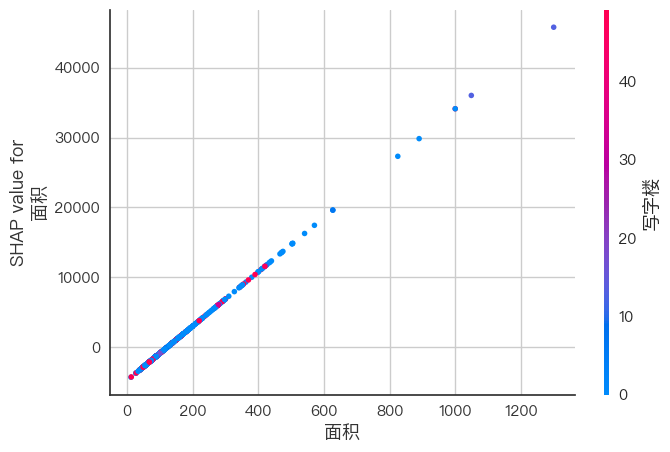
shap.summary_plot(shap_values, X_test) # 点图版本
# 特征依赖图 - 分析单个特征效应
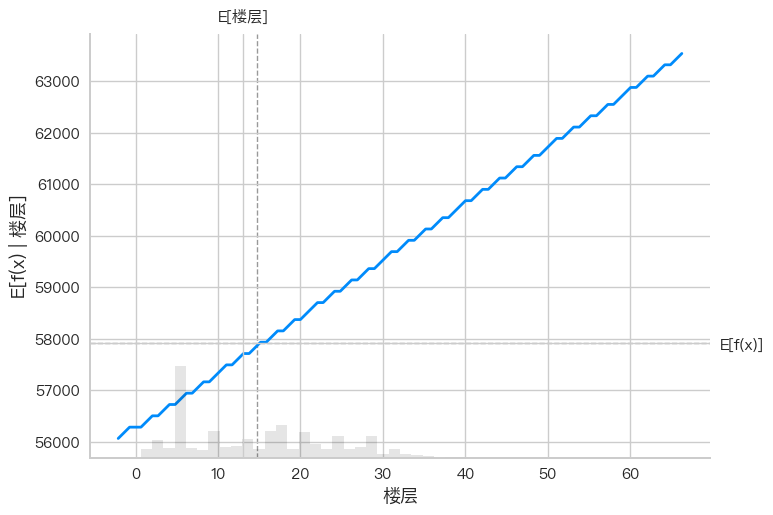
shap.dependence_plot("面积", shap_values, X_test) # 替换"地铁"为您的特征名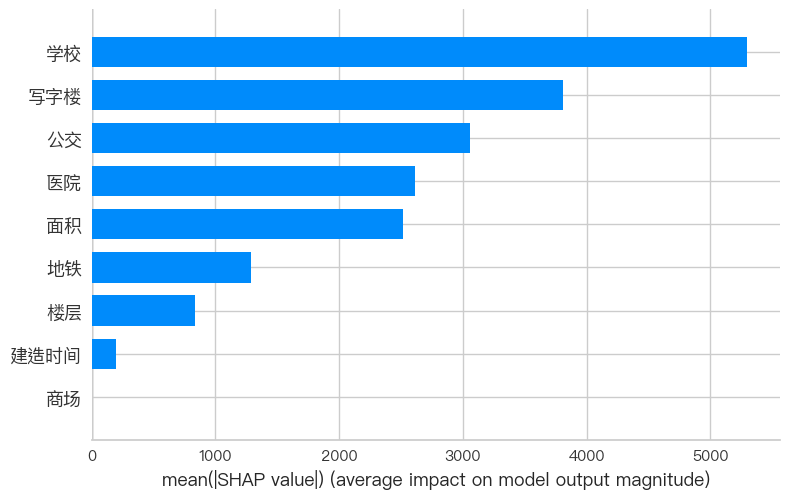
# features = pd.DataFrame(features, columns=["楼层"]) # 根据实际情况修改列名
shap.partial_dependence_plot(
"楼层",
model.predict,
features,
ice=False,
model_expected_value=True,
feature_expected_value=True,
)
附录1. 常用机器学习模型评估方式¶
分类模型评估¶
- 准确率 (Accuracy): 正确预测的比例
- 精确率 (Precision): 预测为正的样本中真正为正的比例
- 召回率 (Recall): 实际为正的样本中被正确预测的比例
- F1分数: 精确率和召回率的调和平均
- ROC曲线与AUC: 评估模型的区分能力
- 混淆矩阵: 直观展示分类结果的各类错误
- 对数损失 (Log Loss): 评估概率预测的不确定性
回归模型评估¶
- 均方误差 (MSE): 预测值与真实值差的平方的平均值
- 均方根误差 (RMSE): MSE的平方根,与因变量同单位
- 平均绝对误差 (MAE): 预测值与真实值的绝对差的平均值
- 平均绝对百分比误差 (MAPE): 相对误差的平均
- R平方 (R²): 模型解释的方差比例
- 调整R平方: 考虑特征数量的R²修正版
交叉验证技术¶
- K折交叉验证: 将数据分成K份,轮流用K-1份训练,1份测试
- 留一交叉验证 (LOOCV): 每次留一个样本作为测试集
- 分层交叉验证: 保持各折中类别分布一致
- 时间序列交叉验证: 考虑时间顺序的特殊交叉验证方法
其他评估技术¶
- 学习曲线: 评估模型随训练集大小变化的表现
- 验证曲线: 评估模型随超参数变化的表现
- Bootstrap: 通过重采样评估模型稳定性
- A/B测试: 在实际环境中比较模型效果
- 残差分析: 检查残差分布评估模型假设
业务驱动的评估¶
- 业务KPI改善: 如转化率、留存率提升
- 模型收益 (Gain) 和提升度 (Lift): 相对于基准的改进
- 模型解释性: 特征重要性、SHAP值等可解释指标
- 计算效率: 推理时间、资源消耗等
附录2. 工业界模型评估指标汇总¶
工业界评估机器学习模型时,通常会关注以下几类指标:
1. 性能指标¶
分类模型¶
- 准确率 (Accuracy): 正确预测的比例
- 精确率 (Precision): 预测为正例中真正例的比例
- 召回率 (Recall): 真实正例中被正确预测的比例
- F1分数: 精确率和召回率的调和平均
- AUC-ROC: ROC曲线下面积,评估分类器区分能力
- PR-AUC: 精确率-召回率曲线下面积
- 混淆矩阵: 预测与实际标签的对比矩阵
回归模型¶
- 均方误差 (MSE): 预测值与真实值差异的平方的平均值
- 均方根误差 (RMSE): MSE的平方根,与目标值同单位
- 平均绝对误差 (MAE): 误差绝对值的平均
- 平均绝对百分比误差 (MAPE): 相对误差的平均
- R²: 模型解释的方差比例
- 调整后的R²: 考虑特征数量的R²校正版本
2. 业务价值指标¶
- 收益提升 (Gain): 模型带来的额外收益
- 投资回报率 (ROI): 模型成本与收益比
- 成本节约: 模型减少的成本开支
- 客户留存改善: 模型提高的客户留存率
- 提升度 (Lift): 模型相较随机分配的改进比例
- 业务KPI改善: 如点击率、转化率提升百分比
3. 计算效率指标¶
- 推理时间: 单次预测所需的时间
- 吞吐量: 单位时间内可处理的预测量
- 内存占用: 模型运行所需的内存资源
- 延迟: 从输入到输出的时间延迟
- CPU/GPU使用率: 计算资源使用效率
- 批处理效率: 批量处理时的资源利用情况
4. 鲁棒性指标¶
- 数据漂移检测: 模型对输入分布变化的敏感度
- 概念漂移检测: 模型对目标关系变化的敏感度
- 异常值敏感性: 模型对异常数据的稳定性
- 特征缺失容忍度: 处理特征缺失的能力
- 对抗样本鲁棒性: 对恶意构造输入的抵抗能力
5. 公平性与伦理指标¶
- 人口统计平等: 不同人群的预测表现差异
- 等比例分类: 不同敏感群体的分类错误率比例
- 公平性评分: 针对特定伦理考量的综合评分
- 偏见检测指标: 检测并量化模型偏见
6. 可解释性指标¶
- 特征重要性: 不同特征对预测的贡献程度
- 部分依赖图: 特定特征与预测结果的关系
- SHAP值: 基于博弈论的特征贡献分析
- 局部解释一致性: 局部解释的稳定性
7. 生产系统指标¶
- 模型版本跟踪: 不同版本模型的表现对比
- 再训练频率: 模型更新的周期和触发条件
- 数据质量监控: 输入数据质量的变化监测
- 预测分布监控: 预测值分布的稳定性追踪
- 模型健康度: 综合评估模型运行状态的指标
注意: 工业界通常会根据具体业务场景和模型类型,从上述指标中选择最相关的几项进行重点监控和优化。
附录3. 数据准备¶
首先,我们使用 Faker 库创建一个更真实的北京市住房数据集,包含影响房价的关键因素:
数据集特征:¶
- 地理信息:北京各区域及其特征(距离市中心、地铁密度、学区质量)
- 房屋特征:面积、房间数、楼层、建造年份、装修程度
- 配套设施:地铁站数量、商业设施、绿化率
- 特殊属性:学区房、房屋朝向、建筑类型、产权年限
from faker import Faker
import random
# 使用 Faker 库创建更真实的北京市住房数据集
np.random.seed(42)
n_samples = 1000
# 北京各区域及其特征
beijing_districts = {
'东城区': {'center_distance': 2, 'metro_density': 0.9, 'school_quality': 0.9},
'西城区': {'center_distance': 3, 'metro_density': 0.8, 'school_quality': 0.95},
'朝阳区': {'center_distance': 8, 'metro_density': 0.7, 'school_quality': 0.6},
'海淀区': {'center_distance': 12, 'metro_density': 0.6, 'school_quality': 0.9},
'丰台区': {'center_distance': 15, 'metro_density': 0.5, 'school_quality': 0.4},
'石景山区': {'center_distance': 18, 'metro_density': 0.4, 'school_quality': 0.3},
'通州区': {'center_distance': 25, 'metro_density': 0.3, 'school_quality': 0.2},
'大兴区': {'center_distance': 30, 'metro_density': 0.2, 'school_quality': 0.1}
}
# 生成特征数据
data = {
'区域': [fake.random_element(elements=list(beijing_districts.keys())) for _ in range(n_samples)],
'面积': [fake.random_int(min=30, max=200) for _ in range(n_samples)], # 房屋面积(平方米)
'房间数': [fake.random_int(min=1, max=5) for _ in range(n_samples)], # 房间数
'楼层': [fake.random_int(min=1, max=30) for _ in range(n_samples)], # 楼层
'建造年份': [fake.random_int(min=1990, max=2023) for _ in range(n_samples)], # 建造年份
'装修程度': [np.random.choice([1, 2, 3, 4, 5], p=[0.1, 0.2, 0.3, 0.3, 0.1]) for _ in range(n_samples)], # 装修程度
'学区房': [fake.boolean(chance_of_getting_true=30) for _ in range(n_samples)], # 是否为学区房
'地铁站数量': [fake.random_int(min=0, max=5) for _ in range(n_samples)], # 附近地铁站数量
'商业设施': [fake.random_int(min=0, max=10) for _ in range(n_samples)], # 附近商业设施数量
'绿化率': [fake.random_int(min=10, max=80) for _ in range(n_samples)] # 小区绿化率
}
# 根据区域计算距离市中心的距离
def calculate_center_distance(district):
return beijing_districts[district]['center_distance'] + fake.random_int(min=0, max=5)
def calculate_metro_distance(district):
base_distance = 5 - beijing_districts[district]['metro_density'] * 4
return max(0.1, base_distance + fake.random_int(min=0, max=3))
# 添加计算的距离特征
data['距离市中心'] = [calculate_center_distance(district) for district in data['区域']]
data['地铁距离'] = [calculate_metro_distance(district) for district in data['区域']]
# 创建DataFrame
df = pd.DataFrame(data)
# 生成更真实的房价(基于北京房价特征)
def calculate_house_price(row):
"""基于特征计算房价"""
base_price = 30000 # 基础价格(元/平方米)
# 区域影响(不同区域基础价格不同)
district_multiplier = {
'东城区': 1.8, '西城区': 1.9, '朝阳区': 1.6, '海淀区': 1.7,
'丰台区': 1.2, '石景山区': 1.1, '通州区': 0.8, '大兴区': 0.7
}
# 面积影响(面积越大,单价可能略低)
area_factor = 1.0 if row['面积'] <= 90 else 0.95 if row['面积'] <= 120 else 0.9
# 楼层影响(中间楼层更贵)
floor_factor = 1.0
if 5 <= row['楼层'] <= 15:
floor_factor = 1.05
elif row['楼层'] > 25:
floor_factor = 0.95
# 年份影响(越新越贵)
year_factor = 1.0 + (2023 - row['建造年份']) * 0.01
# 距离影响
center_factor = max(0.5, 1.0 - row['距离市中心'] * 0.02)
metro_factor = max(0.7, 1.0 - row['地铁距离'] * 0.1)
# 学区房影响
school_factor = 1.3 if row['学区房'] else 1.0
# 装修程度影响
decoration_factor = 0.8 + row['装修程度'] * 0.05
# 地铁站数量影响
metro_station_factor = 1.0 + row['地铁站数量'] * 0.02
# 商业设施影响
commercial_factor = 1.0 + row['商业设施'] * 0.01
# 绿化率影响
green_factor = 0.9 + row['绿化率'] * 0.002
# 计算最终价格
price_per_sqm = (base_price * district_multiplier[row['区域']] *
area_factor * floor_factor * year_factor *
center_factor * metro_factor * school_factor *
decoration_factor * metro_station_factor *
commercial_factor * green_factor)
# 添加一些随机波动
price_per_sqm *= np.random.uniform(0.9, 1.1)
return price_per_sqm * row['面积']
# 计算房价
df['房价'] = df.apply(calculate_house_price, axis=1)
# 添加一些额外的真实特征
df['小区名称'] = [fake.company() + '小区' for _ in range(n_samples)]
df['房屋朝向'] = [fake.random_element(elements=['南', '北', '东', '西', '东南', '西南', '东北', '西北']) for _ in range(n_samples)]
df['建筑类型'] = [np.random.choice(['板楼', '塔楼', '板塔结合'], p=[0.4, 0.4, 0.2]) for _ in range(n_samples)]
df['产权年限'] = [fake.random_element(elements=[70, 50, 40]) for _ in range(n_samples)]
print(f"数据集创建完成!共 {len(df)} 条记录")
print(f"房价范围: {df['房价'].min():.0f} - {df['房价'].max():.0f} 元")
print(f"平均房价: {df['房价'].mean():.0f} 元")
print(f"房价中位数: {df['房价'].median():.0f} 元")
print(f"数据集形状: {df.shape}")
print("\n数据集前5行:")
print(df.head())
数据集创建完成!共 1000 条记录
房价范围: 265016 - 13003649 元
平均房价: 3132873 元
房价中位数: 2397374 元
数据集形状: (1000, 17)
数据集前5行:
区域 面积 房间数 楼层 建造年份 装修程度 学区房 地铁站数量 商业设施 绿化率 距离市中心 地铁距离 \
0 西城区 53 5 15 1995 3 False 3 9 24 5 1.8
1 东城区 199 4 15 2015 5 False 2 4 19 7 3.4
2 丰台区 84 2 1 1992 4 True 5 9 12 19 3.0
3 海淀区 194 2 14 2022 3 True 4 4 71 14 3.6
4 海淀区 193 1 7 2023 2 True 0 0 65 12 4.6
房价 小区名称 房屋朝向 建筑类型 产权年限
0 2.921612e+06 富罳网络有限公司小区 东南 板楼 50
1 7.092217e+06 南康科技有限公司小区 东南 板楼 40
2 2.660846e+06 襄樊地球村信息有限公司小区 东 板塔结合 70
3 7.198861e+06 佳禾网络有限公司小区 东南 板楼 50
4 6.329030e+06 济南亿次元网络有限公司小区 西北 板楼 50
# 查看数据集基本信息
print("=== 数据集概览 ===")
print(f"数据集形状: {df.shape}")
print(f"特征列数: {df.shape[1]}")
print(f"样本数量: {df.shape[0]}")
print("\n=== 前5行数据 ===")
print(df.head())
print("\n=== 数据类型 ===")
print(df.dtypes)
print("\n=== 基本统计信息 ===")
print(df.describe())
print("\n=== 区域分布 ===")
print(df['区域'].value_counts())
print("\n=== 房价统计 ===")
print(f"最高房价: {df['房价'].max():,.0f} 元")
print(f"最低房价: {df['房价'].min():,.0f} 元")
print(f"平均房价: {df['房价'].mean():,.0f} 元")
print(f"房价中位数: {df['房价'].median():,.0f} 元")
print(f"房价标准差: {df['房价'].std():,.0f} 元")
=== 数据集概览 ===
数据集形状: (1000, 17)
特征列数: 17
样本数量: 1000
=== 前5行数据 ===
区域 面积 房间数 楼层 建造年份 装修程度 学区房 地铁站数量 商业设施 绿化率 距离市中心 地铁距离 \
0 西城区 53 5 15 1995 3 False 3 9 24 5 1.8
1 东城区 199 4 15 2015 5 False 2 4 19 7 3.4
2 丰台区 84 2 1 1992 4 True 5 9 12 19 3.0
3 海淀区 194 2 14 2022 3 True 4 4 71 14 3.6
4 海淀区 193 1 7 2023 2 True 0 0 65 12 4.6
房价 小区名称 房屋朝向 建筑类型 产权年限
0 2.921612e+06 富罳网络有限公司小区 东南 板楼 50
1 7.092217e+06 南康科技有限公司小区 东南 板楼 40
2 2.660846e+06 襄樊地球村信息有限公司小区 东 板塔结合 70
3 7.198861e+06 佳禾网络有限公司小区 东南 板楼 50
4 6.329030e+06 济南亿次元网络有限公司小区 西北 板楼 50
=== 数据类型 ===
区域 object
面积 int64
房间数 int64
楼层 int64
建造年份 int64
装修程度 int64
学区房 bool
地铁站数量 int64
商业设施 int64
绿化率 int64
距离市中心 int64
地铁距离 float64
房价 float64
小区名称 object
房屋朝向 object
建筑类型 object
产权年限 int64
dtype: object
=== 基本统计信息 ===
面积 房间数 楼层 建造年份 装修程度 \
count 1000.000000 1000.000000 1000.000000 1000.000000 1000.000000
mean 117.626000 3.071000 15.083000 2006.649000 3.060000
std 49.569742 1.396391 8.829727 9.906055 1.152271
min 30.000000 1.000000 1.000000 1990.000000 1.000000
25% 71.000000 2.000000 7.000000 1998.000000 2.000000
50% 119.500000 3.000000 15.000000 2006.000000 3.000000
75% 160.000000 4.000000 23.000000 2015.000000 4.000000
max 200.000000 5.000000 30.000000 2023.000000 5.000000
地铁站数量 商业设施 绿化率 距离市中心 地铁距离 \
count 1000.000000 1000.000000 1000.000000 1000.000000 1000.000000
mean 2.582000 4.931000 45.475000 16.945000 4.328000
std 1.704166 3.202576 20.446649 9.631237 1.457883
min 0.000000 0.000000 10.000000 2.000000 1.400000
25% 1.000000 2.000000 27.000000 8.000000 3.200000
50% 3.000000 5.000000 46.000000 16.000000 4.400000
75% 4.000000 8.000000 64.000000 25.000000 5.400000
max 5.000000 10.000000 80.000000 35.000000 7.200000
房价 产权年限
count 1.000000e+03 1000.00000
mean 3.132873e+06 53.89000
std 2.328920e+06 12.42265
min 2.650164e+05 40.00000
25% 1.349986e+06 40.00000
50% 2.397374e+06 50.00000
75% 4.399466e+06 70.00000
max 1.300365e+07 70.00000
=== 区域分布 ===
区域
丰台区 141
海淀区 137
大兴区 136
西城区 133
通州区 128
东城区 110
石景山区 109
朝阳区 106
Name: count, dtype: int64
=== 房价统计 ===
最高房价: 13,003,649 元
最低房价: 265,016 元
平均房价: 3,132,873 元
房价中位数: 2,397,374 元
房价标准差: 2,328,920 元
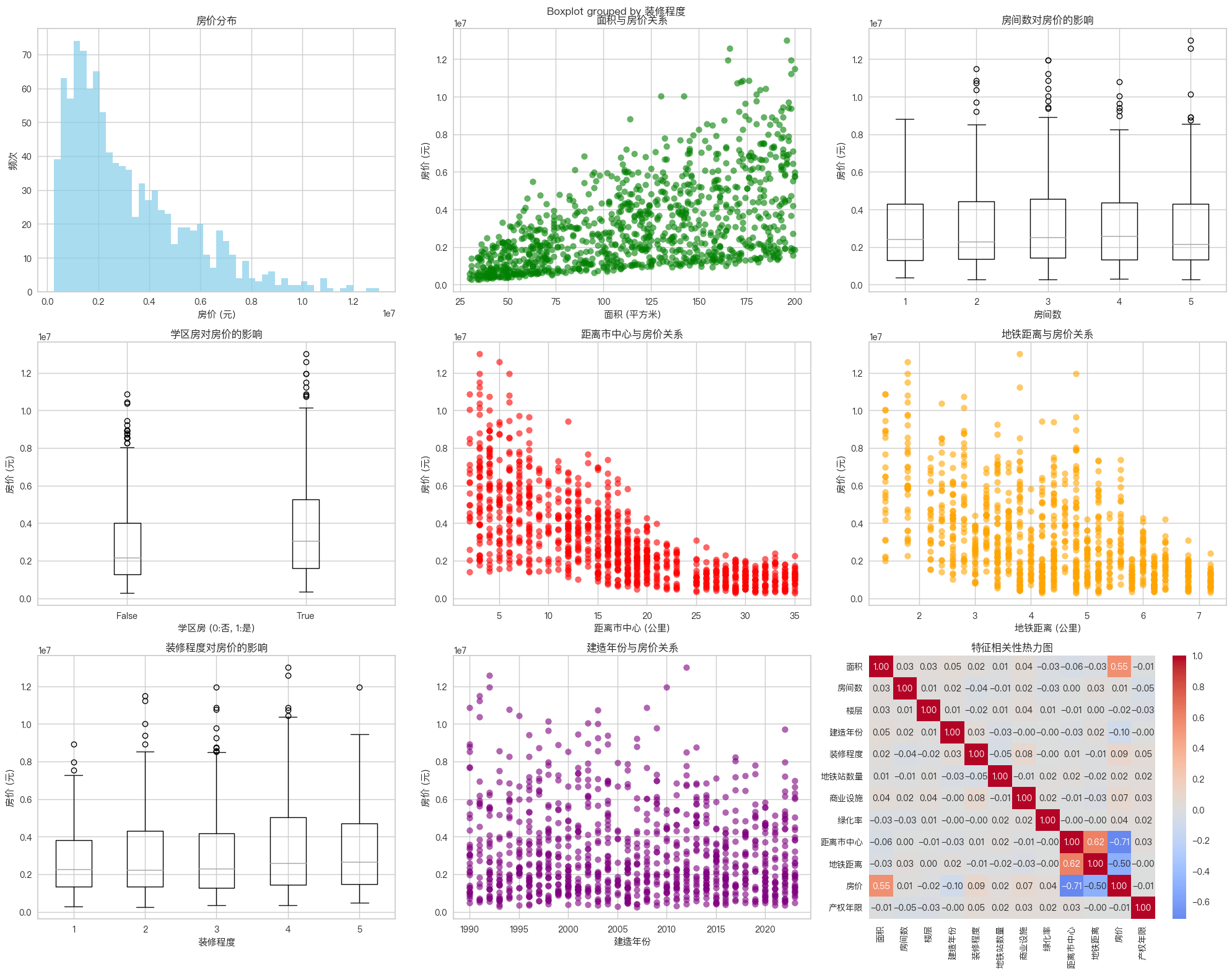
# 数据探索性分析
print("数据集基本信息:")
print(df.describe())
# 可视化分析
plt.figure(figsize=(20, 16))
# 房价分布
plt.subplot(3, 3, 1)
plt.hist(df['房价'], bins=50, alpha=0.7, color='skyblue')
plt.title('房价分布')
plt.xlabel('房价 (元)')
plt.ylabel('频次')
# 面积与房价关系
plt.subplot(3, 3, 2)
plt.scatter(df['面积'], df['房价'], alpha=0.6, color='green')
plt.title('面积与房价关系')
plt.xlabel('面积 (平方米)')
plt.ylabel('房价 (元)')
# 房间数与房价关系
plt.subplot(3, 3, 3)
df.boxplot(column='房价', by='房间数', ax=plt.gca())
plt.title('房间数对房价的影响')
plt.xlabel('房间数')
plt.ylabel('房价 (元)')
# 学区房对房价的影响
plt.subplot(3, 3, 4)
df.boxplot(column='房价', by='学区房', ax=plt.gca())
plt.title('学区房对房价的影响')
plt.xlabel('学区房 (0:否, 1:是)')
plt.ylabel('房价 (元)')
# 距离市中心与房价关系
plt.subplot(3, 3, 5)
plt.scatter(df['距离市中心'], df['房价'], alpha=0.6, color='red')
plt.title('距离市中心与房价关系')
plt.xlabel('距离市中心 (公里)')
plt.ylabel('房价 (元)')
# 地铁距离与房价关系
plt.subplot(3, 3, 6)
plt.scatter(df['地铁距离'], df['房价'], alpha=0.6, color='orange')
plt.title('地铁距离与房价关系')
plt.xlabel('地铁距离 (公里)')
plt.ylabel('房价 (元)')
# 装修程度对房价的影响
plt.subplot(3, 3, 7)
df.boxplot(column='房价', by='装修程度', ax=plt.gca())
plt.title('装修程度对房价的影响')
plt.xlabel('装修程度')
plt.ylabel('房价 (元)')
# 建造年份与房价关系
plt.subplot(3, 3, 8)
plt.scatter(df['建造年份'], df['房价'], alpha=0.6, color='purple')
plt.title('建造年份与房价关系')
plt.xlabel('建造年份')
plt.ylabel('房价 (元)')
# 特征相关性热力图
plt.subplot(3, 3, 9)
# 选择数值列进行相关性分析
numeric_columns = df.select_dtypes(include=[np.number]).columns
correlation_matrix = df[numeric_columns].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0, fmt='.2f')
plt.title('特征相关性热力图')
plt.tight_layout()
plt.show()
数据集基本信息:
面积 房间数 楼层 建造年份 装修程度 \
count 1000.000000 1000.000000 1000.000000 1000.000000 1000.000000
mean 117.626000 3.071000 15.083000 2006.649000 3.060000
std 49.569742 1.396391 8.829727 9.906055 1.152271
min 30.000000 1.000000 1.000000 1990.000000 1.000000
25% 71.000000 2.000000 7.000000 1998.000000 2.000000
50% 119.500000 3.000000 15.000000 2006.000000 3.000000
75% 160.000000 4.000000 23.000000 2015.000000 4.000000
max 200.000000 5.000000 30.000000 2023.000000 5.000000
地铁站数量 商业设施 绿化率 距离市中心 地铁距离 \
count 1000.000000 1000.000000 1000.000000 1000.000000 1000.000000
mean 2.582000 4.931000 45.475000 16.945000 4.328000
std 1.704166 3.202576 20.446649 9.631237 1.457883
min 0.000000 0.000000 10.000000 2.000000 1.400000
25% 1.000000 2.000000 27.000000 8.000000 3.200000
50% 3.000000 5.000000 46.000000 16.000000 4.400000
75% 4.000000 8.000000 64.000000 25.000000 5.400000
max 5.000000 10.000000 80.000000 35.000000 7.200000
房价 产权年限
count 1.000000e+03 1000.00000
mean 3.132873e+06 53.89000
std 2.328920e+06 12.42265
min 2.650164e+05 40.00000
25% 1.349986e+06 40.00000
50% 2.397374e+06 50.00000
75% 4.399466e+06 70.00000
max 1.300365e+07 70.00000
附录3. 模型训练与预测¶
现在我们将使用多元线性回归模型来预测房价:
# 准备特征和目标变量
X = df.select_dtypes(include=[np.number]).drop('房价', axis=1)
y = df['房价']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# 预测
y_pred = model.predict(X_test_scaled)
# 模型评估
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("模型评估结果:")
print(f"均方误差 (MSE): {mse:,.2f}")
print(f"均方根误差 (RMSE): {rmse:,.2f}")
print(f"决定系数 (R²): {r2:.3f}")
# 特征重要性分析
feature_importance = pd.DataFrame({
'特征': X.columns,
'系数': model.coef_
}).sort_values('系数', key=abs, ascending=False)
print("\n特征重要性 (按系数绝对值排序):")
display(feature_importance)
Loading...
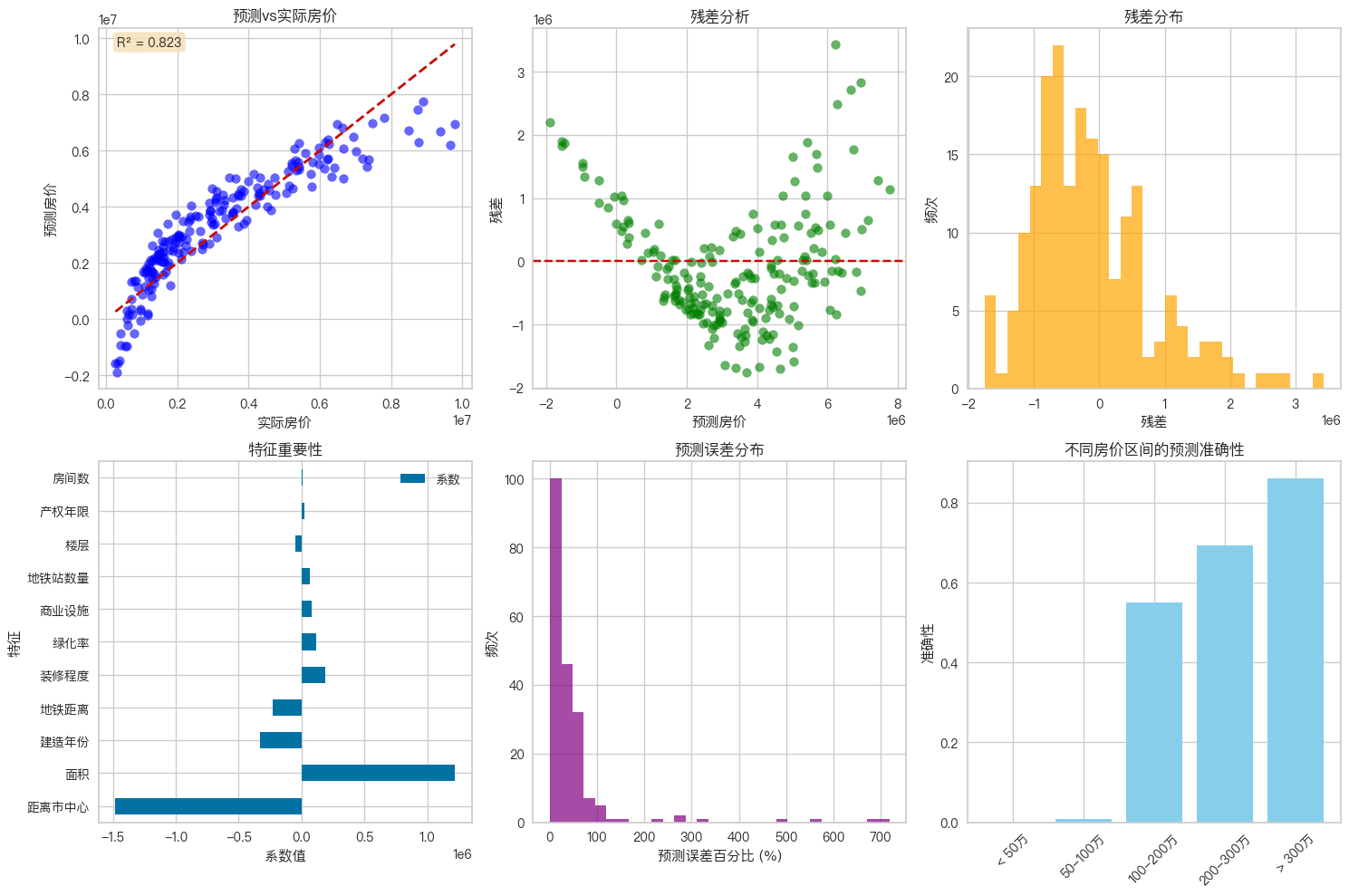
# 可视化预测结果
plt.figure(figsize=(15, 10))
# 预测vs实际
plt.subplot(2, 3, 1)
plt.scatter(y_test, y_pred, alpha=0.6, color='blue')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)
plt.xlabel('实际房价')
plt.ylabel('预测房价')
plt.title('预测vs实际房价')
plt.text(0.05, 0.95, f'R² = {r2:.3f}', transform=plt.gca().transAxes,
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
# 残差分析
plt.subplot(2, 3, 2)
residuals = y_test - y_pred
plt.scatter(y_pred, residuals, alpha=0.6, color='green')
plt.axhline(y=0, color='r', linestyle='--')
plt.xlabel('预测房价')
plt.ylabel('残差')
plt.title('残差分析')
# 残差分布
plt.subplot(2, 3, 3)
plt.hist(residuals, bins=30, alpha=0.7, color='orange')
plt.xlabel('残差')
plt.ylabel('频次')
plt.title('残差分布')
# 特征重要性可视化
plt.subplot(2, 3, 4)
feature_importance.plot(x='特征', y='系数', kind='barh', ax=plt.gca())
plt.title('特征重要性')
plt.xlabel('系数值')
# 预测误差分析
plt.subplot(2, 3, 5)
error_percentage = np.abs((y_test - y_pred) / y_test) * 100
plt.hist(error_percentage, bins=30, alpha=0.7, color='purple')
plt.xlabel('预测误差百分比 (%)')
plt.ylabel('频次')
plt.title('预测误差分布')
# 房价区间预测准确性
plt.subplot(2, 3, 6)
price_ranges = ['< 50万', '50-100万', '100-200万', '200-300万', '> 300万']
range_accuracy = []
for i, (min_price, max_price) in enumerate([(0, 500000), (500000, 1000000),
(1000000, 2000000), (2000000, 3000000), (3000000, float('inf'))]):
mask = (y_test >= min_price) & (y_test < max_price)
if mask.sum() > 0:
accuracy = 1 - np.mean(np.abs((y_test[mask] - y_pred[mask]) / y_test[mask]))
range_accuracy.append(max(0, accuracy))
else:
range_accuracy.append(0)
plt.bar(price_ranges, range_accuracy, color='skyblue')
plt.title('不同房价区间的预测准确性')
plt.ylabel('准确性')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
残差分析详解¶
1. 什么是残差分析?¶
残差(Residual) 是指实际值与预测值之间的差异,即:
残差分析的目的:
- 验证模型假设:检查线性回归的基本假设是否成立
- 识别模型问题:发现非线性关系、异方差性、异常值等
- 评估模型质量:判断模型是否充分捕捉了数据中的模式
- 指导模型改进:为模型优化提供方向
线性回归的基本假设:
- 线性关系:自变量与因变量之间存在线性关系
- 独立性:观测值之间相互独立
- 正态性:残差服从正态分布
- 同方差性:残差的方差在所有预测值水平上保持恒定
2. 如何解读上面的6个子图?¶
| 子图 | 名称 | 目的 | 理想情况/解读 | 问题识别 |
|---|---|---|---|---|
| 1 | 预测vs实际房价 | 评估模型的整体预测准确性 | • 点越接近红色对角线,预测越准确 • 点的分散程度反映预测误差大小 • R²值显示模型解释的方差比例 | • 点偏离对角线:预测存在系统性偏差 • 点分散严重:模型预测不稳定 |
| 2 | 残差分析(最重要) | 检查残差是否随机分布 | • 残差围绕0线随机分布 • 无明显模式或趋势 • 方差保持恒定 | • 漏斗形:存在异方差性(方差随预测值变化) • 曲线模式:存在非线性关系 • 系统性偏离:模型存在系统性偏差 |
| 3 | 残差分布 | 检查残差是否服从正态分布 | • 钟形分布,中心在0附近 • 对称分布 | • 偏斜分布:存在系统性偏差 • 多峰分布:可能存在未识别的分组 • 非正态分布:违反正态性假设 |
| 4 | 特征重要性 | 识别对预测最重要的特征 | • 系数绝对值越大,特征影响越大 • 正系数表示正向影响,负系数表示负向影响 • 帮助理解哪些因素对房价影响最大 | • 系数接近0:特征影响很小 • 系数符号与预期不符:可能存在数据问题 |
| 5 | 预测误差分布 | 评估预测的相对准确性 | • 误差百分比越小,预测越准确 • 分布形状反映预测稳定性 • 帮助识别模型在不同情况下的表现 | • 误差分布偏斜:模型在某些情况下表现不佳 • 误差过大:模型整体预测能力有限 |
| 6 | 不同房价区间的预测准确性 | 评估模型在不同价格区间的表现 | • 准确性越高,模型在该价格区间表现越好 • 帮助识别模型在哪些价格区间需要改进 • 为业务应用提供针对性建议 | • 某些价格区间准确性低:模型在该区间表现不佳 • 准确性差异大:模型对不同价格区间的适应性不同 |
3. 残差分析的实际意义¶
对于房价预测模型:
- 残差分析帮助我们理解模型是否充分捕捉了房价的影响因素
- 识别模型局限性:如某些特殊区域或房型的预测偏差
- 指导特征工程:发现需要添加的新特征或需要变换的现有特征
- 评估模型可靠性:为实际应用提供信心度评估