Numeric data tends to be better-behaved than text data. There’s only so many symbols that appear in numbers and they have well-defined values. Despite its relative cleanliness, there are variety of preprocessing tasks you should consider before using numeric data. In this lesson, we’ll learn some common operations used to prepare numeric data for use in analysis and predictive models.
Centering and Scaling¶
Numeric variables are often on different scales and cover different ranges, so they can’t be easily compared. What’s more, variables with large values can dominate those with smaller values when using certain modeling techniques. Centering and scaling is a common preprocessing task that puts numeric variables on a common scale so no single variable will dominate the others.
The simplest way to center data is to subtract the mean value from each data point. Subtracting the mean centers the data around zero and sets the new mean to zero. Let’s try zero-centering the mtcars dataset, a small set of car-related data.
%matplotlib inline
import numpy as np
import pandas as pdmtcars = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/mtcars.csv")
mtcars.rename(columns={'manufacturer':'model'}, inplace = True)
print (mtcars.head() )
mtcars.index = mtcars.model # Set row index to car model
del mtcars["model"] # Drop car name column
colmeans = mtcars.sum()/mtcars.shape[0] # Get column means
colmeans model mpg cyl disp hp drat wt qsec vs am gear \
0 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4
1 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4
2 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4
3 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3
4 Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3
carb
0 4
1 4
2 1
3 1
4 2
mpg 20.090625
cyl 6.187500
disp 230.721875
hp 146.687500
drat 3.596563
wt 3.217250
qsec 17.848750
vs 0.437500
am 0.406250
gear 3.687500
carb 2.812500
dtype: float64With the column means in hand, we just need to subtract the column means from each row in an element-wise fashion to zero center the data. Pandas performs math operations involving DataFrames and columns on an element-wise row-by-row basis by default, so we can simply subtract our column means series from the data set to center it:
centered = mtcars-colmeans
centered.describe()With zero-centered data, negative values are below average and positive values are above average.
Now that the data is centered, we’d like to put it all on a common scale. One way to put data on a common scale is to divide by the standard deviation. Standard deviation is a statistic that describes the spread of numeric data. The higher the standard deviation, the further the data points tend to be spread away from the mean value. You can get standard deviations with df.std():
# Get column standard deviations
column_deviations = mtcars.std(axis=0)
centered_and_scaled = centered/column_deviations
centered_and_scaled.describe()Notice that after dividing by the standard deviation, every variable now has a standard deviation of 1. At this point, all the columns have roughly the same mean and scale of spread about the mean.
Manually centering and scaling as we’ve done is a good exercise, but it is often possible to perform common data preprocessing automatically using functions built into Python libraries. The Python library scikit-learn, a popular package for predictive modeling and data analysis, has preprocessing tools including a scale() function for centering and scaling data:
from sklearn import preprocessingscaled_data = preprocessing.scale(mtcars) # Scale the data*
scaled_cars = pd.DataFrame(scaled_data, # Remake the DataFrame
index=mtcars.index,
columns=mtcars.columns)
scaled_cars.describe()Note: preprocessing.scale() returns ndarrays so we convert it back into a DataFrame.
Notice that the values are almost the same as those we calculated manually but not exactly the same. These small differences are likely due to rounding and details of the scikit-learn implementation of centering and scaling.
Dealing With Skewed Data¶
The distribution of data--its overall shape and how it is spread out--can have a significant impact on analysis and modeling. Data that is roughly evenly spread around the mean value--known as normally distributed data--tends to be well-behaved. On the other hand, some data sets exhibit significant skewness or asymmetry. To illustrate, let’s generate a few distributions
# Generate normal data*
normally_distributed = np.random.normal(size=10000)
normally_distributed = pd.DataFrame(normally_distributed) # Convert to DF
normally_distributed.hist(figsize=(8,8), # Plot histogram
bins=30); 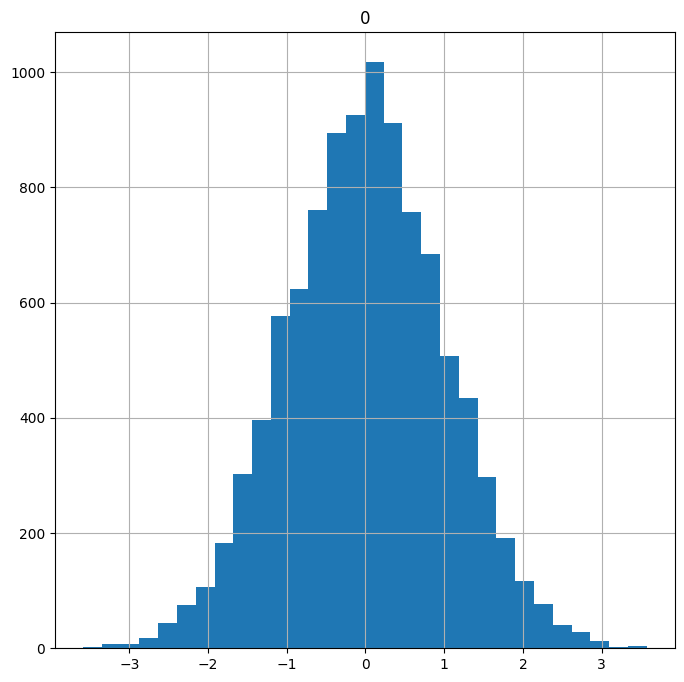
Note: We will cover probability distributions and generating random data in a future lesson.
Notice how the normally distributed data looks roughly symmetric with a bell-shaped curve. Now let’s generate some skewed data:
skewed = np.random.exponential(scale=2, # Generate skewed data
size= 10000)
skewed = pd.DataFrame(skewed) # Convert to DF
skewed.hist(figsize=(8,8), # Plot histogram
bins=50); 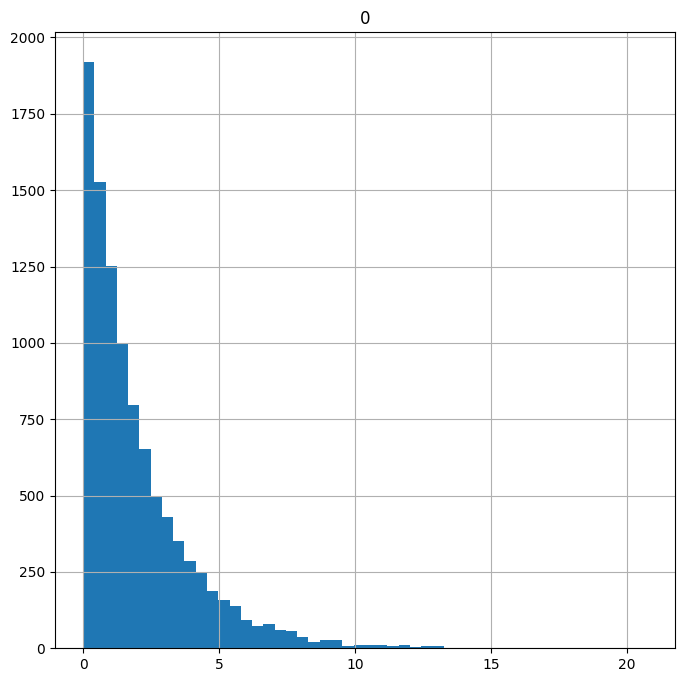
Data with a long tail that goes off to the right is called positively skewed or right skewed. When you have a skewed distribution like the one above, the extreme values in the long tail can have a disproportionately large influence on whatever test you perform or models you build. Reducing skew may improve your results. Taking the square root of each data point or taking the natural logarithm of each data point are two simple transformations that can reduce skew. Let’s see their effects on the skewed data:
# Get the square root of data points*
sqrt_transformed = skewed.apply(np.sqrt)
sqrt_transformed.hist(figsize=(8,8), # Plot histogram
bins=50); 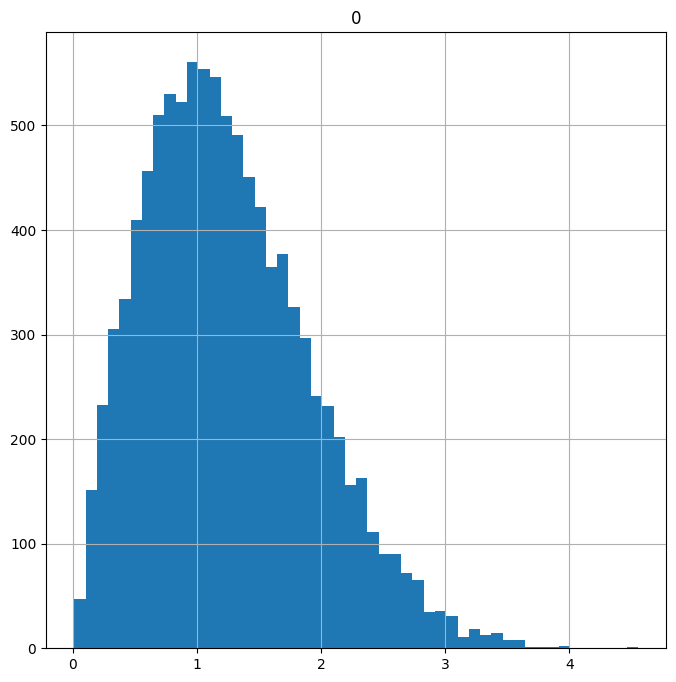
Note: The df.apply() function applies a given function to each row or column of the DataFrame. In this case we pass in np.sqrt to get the square root of each value.
Now let’s look at a log transformation:
log_transformed = (skewed+1).apply(np.log) # Get the log of the data
log_transformed.hist(figsize = (8,8), # Plot histogram
bins=50); 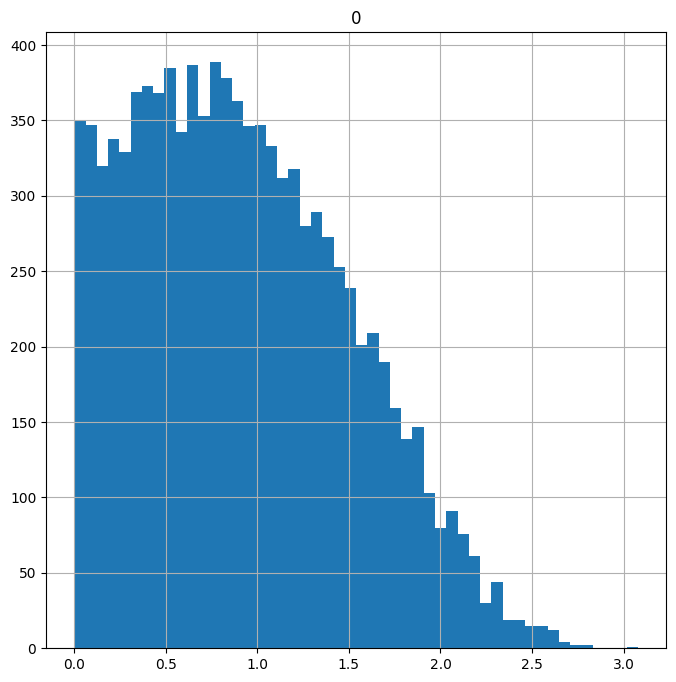
Note: Adding 1 before taking the log ensures we don’t end up with negative values.
Both the sqrt() and log() transforms reduced the skew of the data. It’s still not quite normally distributed, but the amount of extreme data in the tails has been reduced to the point where we might not be so worried about it having a large influence on our results.
Highly Correlated Variables¶
In predictive modeling, each variable you use to construct a model would ideally represent some unique feature of the data. In other words, you want each variable to tell you something different. In reality, variables often exhibit collinearity--a strong correlation or tendency to move together, typically due to some underlying similarity or common influencing factor. Variables with strong correlations can interfere with one another when performing modeling and muddy results.
You can check the pairwise correlations between numeric variables using the df.corr() function:
mtcars.iloc[:,0:6].corr() # Check the pairwise correlations of 6 variablesA positive correlation implies that when one variable goes up the other tends to go up as well. Negative correlations indicate an inverse relationship: when one variable goes up the other tends to go down. A correlation near zero indicates low correlation while a correlation near -1 or 1 indicates a large negative or positive correlation.
Inspecting the data table, we see that the number of cylinders a car has (cyl) and its weight (wt) have fairly strong negative correlations to gas mileage (mpg.). This indicates that heavier cars and cars with more cylinders tend to get lower gas mileage.
A scatter plot matrix can be a helpful visual aide for inspecting collinearity. We can create one with the pandas scatter_matrix() function located in the tools.plotting pandas folder:
from pandas.plotting import scatter_matrix
scatter_matrix(mtcars.iloc[:,0:6], # Make a scatter matrix of 6 columns
figsize=(10, 10), # Set plot size
diagonal='kde'); # Show distribution estimates on diagonal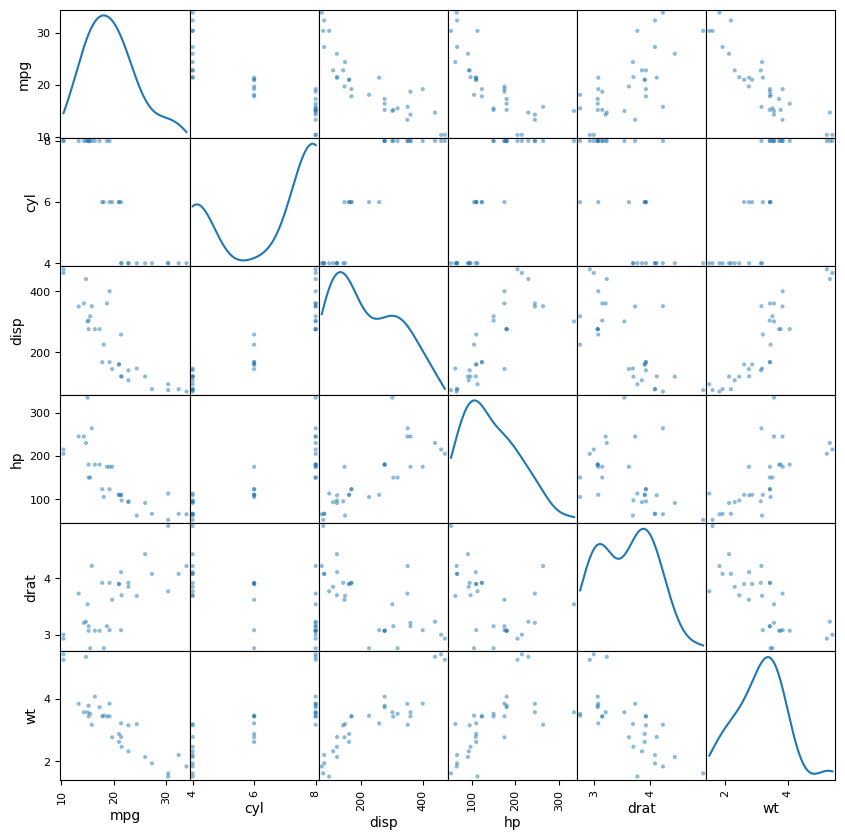
A scatter plot matrix creates pairwise scatter plots that let you visually inspect the relationships between pairs of variables. It can also help identify oddities in the data, such as variables like cyl that only take on values in a small discrete set.
If you find highly correlated variables, there are a few things you can do including:
- Leave them be
- Remove one or more variables
- Combine them in some way
Reducing the number of variables under consideration, either by removing some or by combining them some way is known as “dimensionality reduction.” How you choose to handle correlated variables is ultimately a subjective decision that should be informed by your goal.
Imputing with Sklearn¶
In the lesson on initial data exploration, we explored Titanic survivor data and found that several passengers had missing listed for age. Missing values in numeric data are troublesome because you can’t simply treat them as a category: you have to either remove them or fill them in.
Imputation describes filling in missing data with estimates based on the rest of the data set. When working with the titanic data set, we set all the missing Age values to the median age for the data set. Other simple imputation methods include setting missing values to the mean or most common value (mode.). The scikit-learn offers an Imupter tool that can automatically carry out these imputations for us. Let’s start by loading the Imputer and introducing some missing values into the mpg data:
# The following line sets a few mpg values to None
mtcars["mpg"] = np.where(mtcars["mpg"]>22, None, mtcars["mpg"])
mtcars["mpg"] # Confirm that missing values were addedmodel
Mazda RX4 21.0
Mazda RX4 Wag 21.0
Datsun 710 None
Hornet 4 Drive 21.4
Hornet Sportabout 18.7
Valiant 18.1
Duster 360 14.3
Merc 240D None
Merc 230 None
Merc 280 19.2
Merc 280C 17.8
Merc 450SE 16.4
Merc 450SL 17.3
Merc 450SLC 15.2
Cadillac Fleetwood 10.4
Lincoln Continental 10.4
Chrysler Imperial 14.7
Fiat 128 None
Honda Civic None
Toyota Corolla None
Toyota Corona 21.5
Dodge Challenger 15.5
AMC Javelin 15.2
Camaro Z28 13.3
Pontiac Firebird 19.2
Fiat X1-9 None
Porsche 914-2 None
Lotus Europa None
Ford Pantera L 15.8
Ferrari Dino 19.7
Maserati Bora 15.0
Volvo 142E 21.4
Name: mpg, dtype: objectNow let’s use the Imputer fill in missing values based on the mean:
from sklearn.impute import SimpleImputer
imp = SimpleImputer(missing_values=np.nan, # Create imputation model
strategy='mean') # Use mean imputation
# axis=0) # Impute by column
imputed_cars = imp.fit_transform(mtcars) # Use imputation model to get values
imputed_cars = pd.DataFrame(imputed_cars, # Remake DataFrame with new values
index=mtcars.index,
columns = mtcars.columns)
imputed_cars.head(10)Imputer supports the “mean”, “median” and “most_frequent” (mode) as strategies for imputation.
Other imputation methods include filling in values based on “similar” or “neighboring” records (K-nearest-neighbors imputation) and filling in values based on regression models. Using predictive models to fill in missing values adds an extra layer of complexity to an analysis and can significantly increase processing time, although it may result in better predictive performance. We’ll revisit predictive modeling in a future lesson. In the example above, we created missing values by setting the largest mpg values to “NaN”. In this case, it would be difficult to find a good estimate for the missing mpg values, since all the missing values were greater than any of the mpg values we had in hand.
Wrap Up¶
In the past two lessons, we covered a variety of methods for preparing text data and numeric data. The majority of data you encounter will likely fall in one of these two categories, but there is one other type of data that appears with enough frequency that you will have to deal with it sooner or later: dates.